TL;DR: MVSGaussian is a Gaussian-based method designed for efficient reconstruction of unseen scenes from sparse views in a single forward pass. It offers high-quality initialization for fast training and real-time rendering.
Overview Video
Abstract
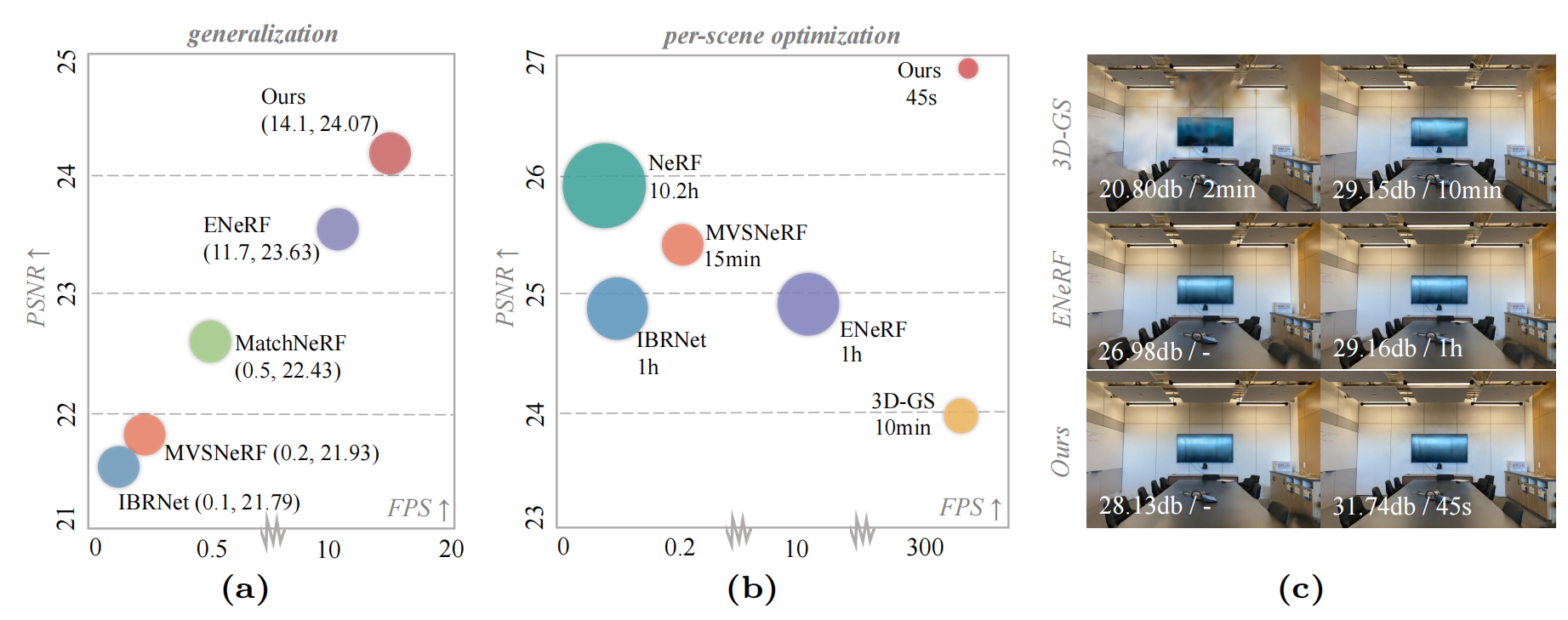
We present MVSGaussian, a new generalizable 3D Gaussian representation approach derived from Multi-View Stereo (MVS) that can efficiently reconstruct unseen scenes. Specifically, 1) we leverage MVS to encode geometry-aware Gaussian representations and decode them into Gaussian parameters. 2) To further enhance performance, we propose a hybrid Gaussian rendering that integrates an efficient volume rendering design for novel view synthesis. 3) To support fast fine-tuning for specific scenes, we introduce a multi-view geometric consistent aggregation strategy to effectively aggregate the point clouds generated by the generalizable model, serving as the initialization for per-scene optimization. Compared with previous generalizable NeRF-based methods, which typically require minutes of fine-tuning and seconds of rendering per image, MVSGaussian achieves real-time rendering with better synthesis quality for each scene. Compared with the vanilla 3D-GS, MVSGaussian achieves better view synthesis with less training computational cost. Extensive experiments on DTU, Real Forward-facing, NeRF Synthetic, and Tanks and Temples datasets validate that MVSGaussian attains state-of-the-art performance with convincing generalizability, real-time rendering speed, and fast per-scene optimization.
Method
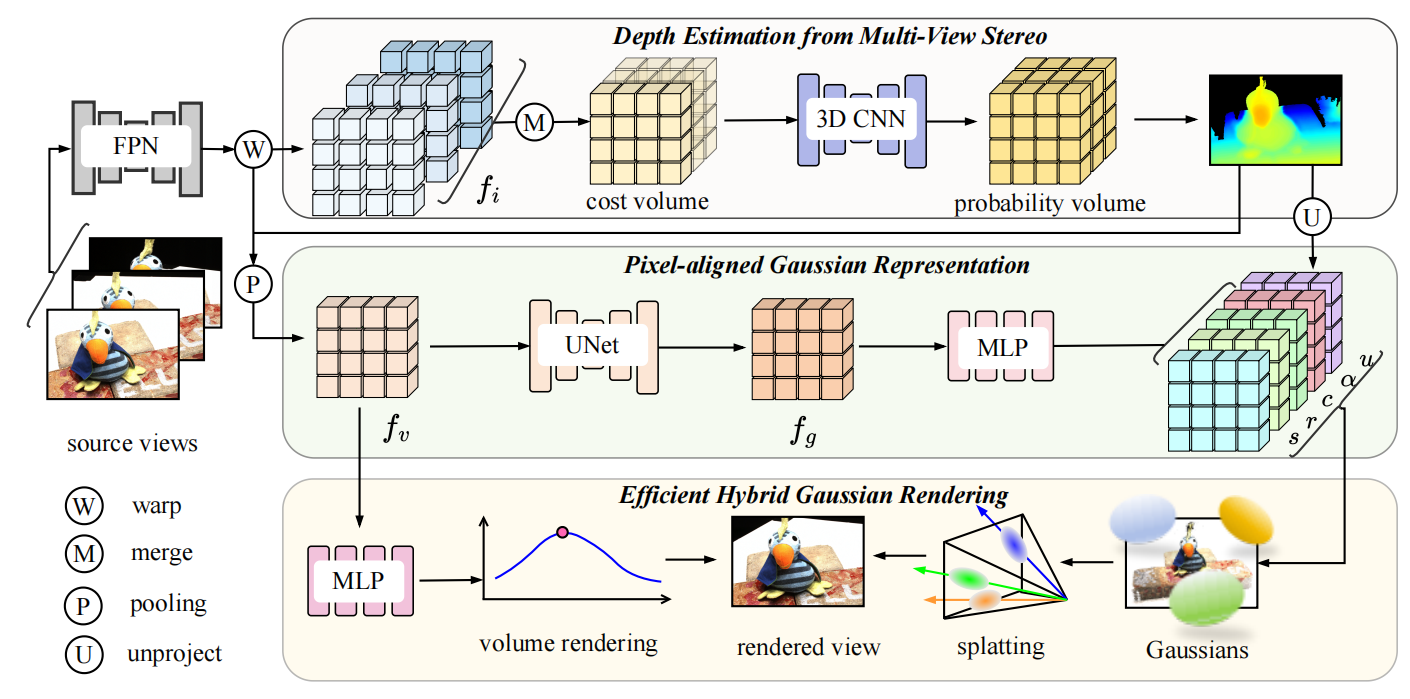
The overview of generalizable Gaussian Splatting framework. MVSGaussian consists of three components: 1) Depth Estimation from Multi-View Stereo. The extracted multi-view features are aggregated into a cost volume, regularized by 3D CNNs to produce depth estimations. 2) Pixel-aligned Gaussian representation. Based on the obtained depth map, we encode features for each pixel-aligned 3D point. 3) Efficient hybrid Gaussian rendering. We add a simple yet effective depth-aware volume rendering module to boost the generalizable performance.
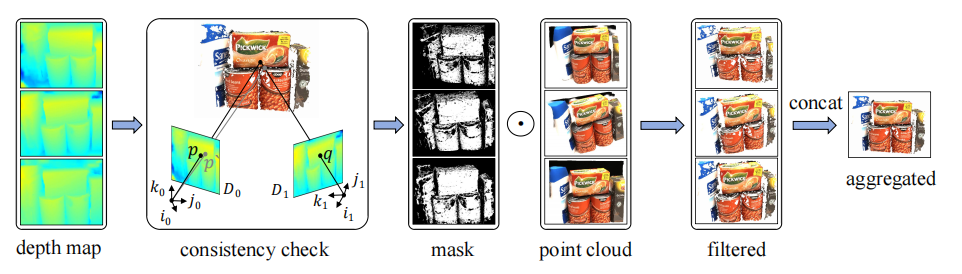
Consistent aggregation. With depth maps and point clouds produced by the generalizable model, we conduct multi-view geometric consistency checks to derive masks for filtering out unreliable points. The filtered point clouds are concatenated to construct a point cloud, serving as the initialization for per-scene optimization.
Generalization results
Qualitative comparison

Video comparsion
Depths
Finetuned results
Qualitative comparison

Ours vs. ENeRF
Ours vs. 3D-GS
Optimization process
BibTeX
@article{liu2024mvsgaussian,
title={Fast Generalizable Gaussian Splatting Reconstruction from Multi-View Stereo},
author={Liu, Tianqi and Wang, Guangcong and Hu, Shoukang and Shen, Liao and Ye, Xinyi and Zang, Yuhang and Cao, Zhiguo and Li, Wei and Liu, Ziwei},
journal={arXiv preprint arXiv:2405.12218},
year={2024}
}
Related Links
MVSNeRF: Fast Generalizable Radiance Field Reconstruction from Multi-View StereoENeRF: Efficient Neural Radiance Fields for Interactive Free-viewpoint Video
IBRNet: Learning Multi-View Image-Based Rendering
GeFu: Geometry-aware Reconstruction and Fusion-refined Rendering for Generalizable Neural Radiance Fields
ET-MVSNet: When Epipolar Constraint Meets Non-local Operators in Multi-View Stereo
DMVSNet: Constraining Depth Map Geometry for Multi-View Stereo: A Dual-Depth Approach with Saddle-shaped Depth Cells
SparseNeRF: Distilling Depth Ranking for Few-shot Novel View Synthesis
GauHuman: Articulated Gaussian Splatting from Monocular Human Videos
